|
I'm a member of technical staff on the pretraining team at Anthropic. Previously, I was a PhD student in the Machine Learning Department at Carnegie Mellon University, advised by Deepak Pathak. My work was supported by the NSF Graduate Research Fellowship. Before that, I was an electrical engineering and computer science major at UC Berkeley, where I received my BS and MS. I was a researcher in the Berkeley Artificial Intelligence Research Lab and was advised by Pieter Abbeel and Lerrel Pinto. I've also spent time as an intern at AI at Meta. Email / CV / Google Scholar / GitHub / Twitter |

|
|
I'm interested in generative models, generalization, and the role of data in deep learning. Some papers are highlighted. |
|
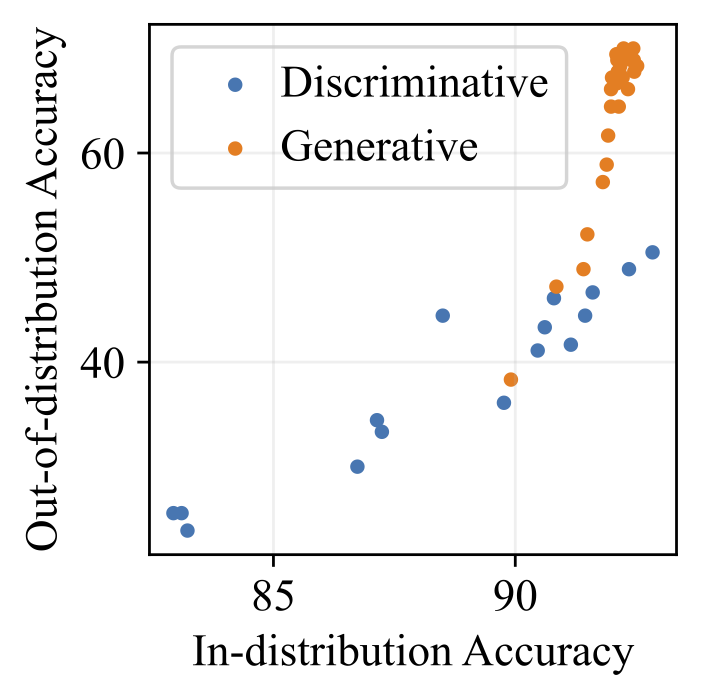
Alexander C. Li, Ananya Kumar, Deepak Pathak ICLR 2025 ICML 2024 Workshop on Structured Probabilistic Inference & Generative Modeling (Oral Presentation) openreview | arxiv | pdf | code | abstract Discriminative approaches to classification often learn shortcuts that hold in-distribution but fail even under minor distribution shift. This failure mode stems from an overreliance on features that are spuriously correlated with the label. We show that classifiers based on class-conditional generative models avoid this issue by modeling all features, both causal and spurious, instead of mainly spurious ones. These generative classifiers are simple to train, avoiding the need for specialized augmentations, strong regularization, extra hyperparameters, or knowledge of the specific spurious correlations to avoid. We find that diffusion-based and autoregressive generative classifiers achieve state-of-the-art performance on standard image and text distribution shift benchmarks and reduce the impact of spurious correlations present in realistic applications, such as satellite or medical datasets. Finally, we carefully analyze a Gaussian toy setting to understand the data properties that affect when generative classifiers outperform discriminative ones. |

|
Alexander C. Li, Yuandong Tian, Beidi Chen, Deepak Pathak, Xinlei Chen NeurIPS 2024 arxiv | pdf | code | abstract Conventional wisdom suggests that pre-training Vision Transformers (ViT) improves downstream performance by learning useful representations. Is this actually true? We investigate this question and find that the features and representations learned during pre-training are not essential. Surprisingly, using only the attention patterns from pre-training (i.e., guiding how information flows between tokens) is sufficient for models to learn high quality features from scratch and achieve comparable downstream performance. We show this by introducing a simple method called attention transfer, where only the attention patterns from a pre-trained teacher ViT are transferred to a student, either by copying or distilling the attention maps. Since attention transfer lets the student learn its own features, ensembling it with a fine-tuned teacher also further improves accuracy on ImageNet. We systematically study various aspects of our findings on the sufficiency of attention maps, including distribution shift settings where they underperform fine-tuning. We hope our exploration provides a better understanding of what pre-training accomplishes and leads to a useful alternative to the standard practice of fine-tuning. |

|
Florian Bardes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, ... (41 total authors) arxiv | pdf | abstract Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos. |

|
Mihir Prabhudesai*, Tsung-Wei Ke*, Alexander C. Li, Deepak Pathak, Katerina Fragkiadaki NeurIPS 2023 arxiv | pdf | project page | code | abstract Our method, Diffusion-TTA, adapts pre-trained discriminative models such as image classifiers, segmenters and depth predictors, to each unlabeled example in the test set using generative feedback from a diffusion model. We achieve this by modulating the conditioning of the diffusion model using the output of the discriminative model. We then maximize the image likelihood objective by backpropagating the gradients to discriminative model’s parameters. We show Diffusion-TTA significantly enhances the accuracy of various large-scale pre-trained discriminative models, such as ImageNet classifiers, CLIP models, image pixel labelers and image depth predictors. Diffusion-TTA outperforms existing test-time adaptation methods, including TTT-MAE and TENT, and particularly shines in online adaptation setups, where the discriminative model is continually adapted to each example in the test set. |
|
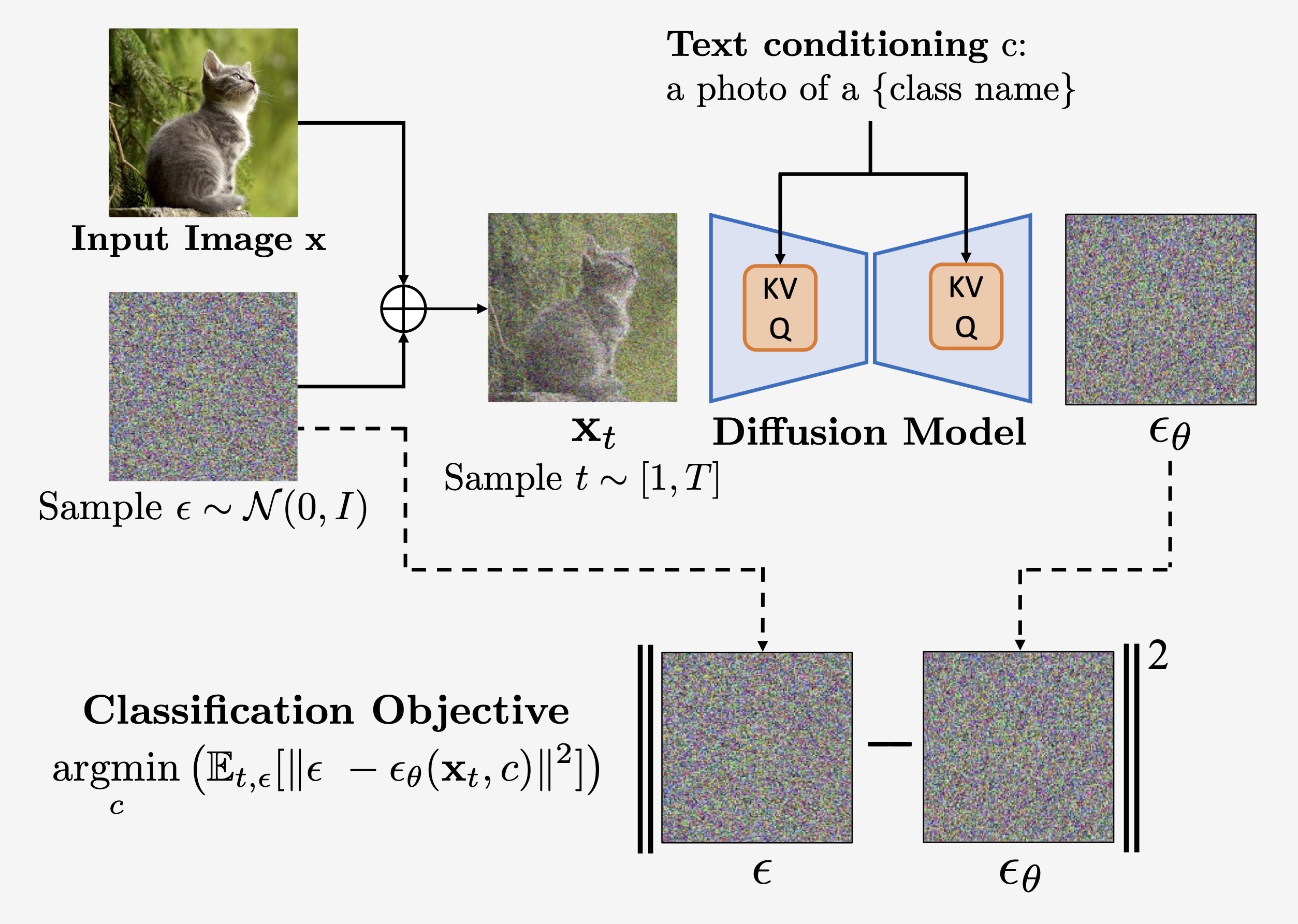
Alexander C. Li, Mihir Prabhudesai, Shivam Duggal, Ellis Brown, Deepak Pathak ICCV 2023 arxiv | pdf | project page | code | abstract We show that density estimates from text-to-image diffusion models like Stable Diffusion can be used for zero-shot classification without any additional training. Our generative approach to classification (Diffusion Classifier) outperforms alternative methods of extracting knowledge from diffusion models and has stronger multimodal reasoning abilities than competing discriminative approaches. Finally, we use Diffusion Classifier to extract standard classifiers from class-conditional diffusion models trained on ImageNet. Even though these diffusion models are trained with weak augmentations and no regularization, we find that they approach the performance of SOTA discriminative ImageNet classifiers. |

|
Alexander C. Li*, Ellis Brown*, Alexei A. Efros, Deepak Pathak ICML 2023 arxiv | pdf | project page | code | abstract We propose dynamically utilizing the Internet to quickly train a small-scale model that does extremely well on the task at hand. Our approach, called Internet Explorer, explores the web in a self-supervised manner to progressively find relevant examples that improve performance on a desired target dataset. It cycles between searching for images on the Internet with text queries, self-supervised training on downloaded images, determining which images were useful, and prioritizing what to search for next. We evaluate Internet Explorer across several datasets and show that it outperforms or matches CLIP oracle performance by using just a single GPU desktop to actively query the Internet for 40 hours. |
|
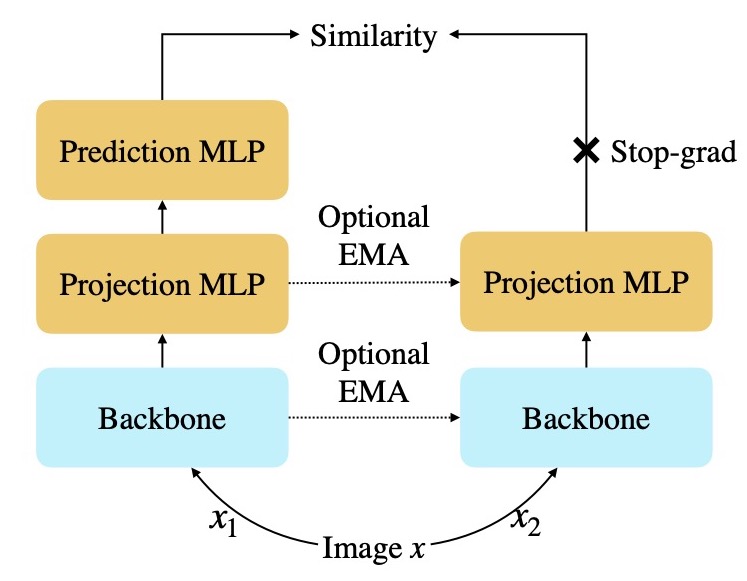
Alexander C. Li, Alexei A. Efros, Deepak Pathak ECCV 2022 arxiv | pdf | project page | code | bibtex | abstract We empirically analyze non-contrastive self-supervised methods and find that SimSiam is extraordinarily sensitive to model size. In particular, SimSiam representations undergo partial dimensional collapse if the model is too small relative to the dataset size. We propose a metric to measure the degree of this collapse and show that it can be used to forecast the downstream task performance without any fine-tuning or labels. Finally, we demonstrate that shifting to a continual learning setting acts as a regularizer, prevents collapse, and can improve linear probe accuracy by up to 18 percentage points with ResNet-18 on ImageNet. |
|
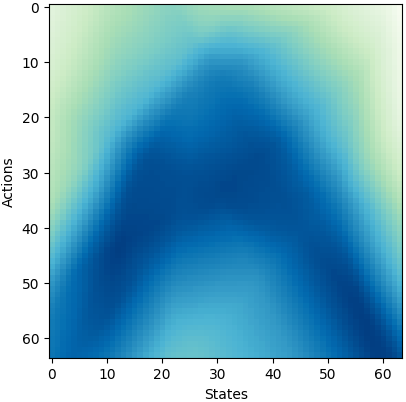
Alexander C. Li, Deepak Pathak NeurIPS 2021 arxiv | pdf | project page | code | bibtex | abstract We propose a simple architecture for RL that controls how quickly the network fits different frequencies in the training data. We explain this behavior using its neural tangent kernel, and use this to prioritize learning low-frequency functions and reduce networks' susceptibility to noise during optimization. Experiments on state-based and image-based RL benchmarks show improved sample-efficiency, as well as robustness to added bootstrap noise. |
|
Alexander C. Li, Lerrel Pinto, Pieter Abbeel NeurIPS 2020 arxiv | pdf | project page | code | bibtex | abstract We present Generalized Hindsight: an approximate inverse reinforcement learning technique for relabeling behaviors with the right tasks. Given a behavior generated under one task, Generalized Hindsight finds a different task that the behavior is better suited for. Relabeling a trajectory with this different task and training with an off-policy RL algorithm improves performance on a suite of multi-task navigation and manipulation tasks. |

|
Alexander C. Li*, Carlos Florensa*, Ignasi Clavera, Pieter Abbeel International Conference on Learning Representations (ICLR), 2020 arxiv | pdf | project page | code | bibtex | abstract We develop a new hierarchical RL algorithm that can efficiently adapt pre-trained skills on related tasks, and directly learn effective emergent skills by simultaneously training the entire hierarchy. |
|
|


|
|
Website template from Jon Barron. |